Nordisk dialektkorpus
Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.
Av Janne Bondi Johannessen, Tekstlaboratoriet, ILN, HF, UiO
Instituttledelsen har bedt meg skrive litt om Nordisk dialektkorpus som en bragd i humaniora. Det gjør jeg gjerne, for det er virkelig noe å fremheve både sett fra innsatsen som er lagt inn av svært mange fagfolk, og ikke minst det gode resultatet. Den norske delen av korpuset samt all den tekniske utviklingen ble gjort i prosjektet Norwegian Dialect Syntax (NorDiaSyn), mens et felles nordisk nettverk, Scandinavian Dialect Syntax, arbeidet for nasjonale prosjekter innen hele Norden, noe som var uvurderlig for å få gjennomført målet om et felles dialektkorpus.
Korpuset er kort sagt en samling av samtaleopptak gjort over hele Norden. Opptakene er transkribert ord for ord, som så er søkbare og gjenfinnbare i en database, og med direkte lenker til relevant sted i opptakene. Selve søkemulighetene er avanserte og innebærer mulighet for en lang rekke lingvistiske kombinasjonsmuligheter kombinert med filtrering mot informantenes bakgrunn (sted, alder, kjønn o.a.). Opptakene er stort sett gjort i prosjektperioden, men vi har også inkludert en del eldre opptak fra Målførearkivet i Oslo.
Arbeidet ble startet i 2006, og korpuset ble klart i 2011 uten forsinkelser. Her er noen fakta som viser omfanget av korpuset.
Om innholdet i korpuset:
Land: 5 (Danmark, Finland, Island, Norge, Sverige)
Språk: 5 (dansk, færøysk, islandsk, norsk, svensk)
År: Etter 2000, samt noen fra 1950-80.
Opptakssteder: 204
Informanter: 745
Antall ord: 2,6 millioner
Om arbeidet:
Opptakene i Norge: 35 personer
Transkripsjon av norsk: 14 personer
Universiteter: 9 universiteter i Norden
Ledelse i NorDiaSyn: Janne Bondi Johannessen (ILN, UiO), i samarbeid med Øystein Alexander Vangsnes (UiT) og Tor Anders Åfarli (NTNU)
Teknisk utvikling og koordinering, grammatisk annotering: Tekstlab, ILN, UiO.
Finansiering: I Norge: NFR (FRIHUM), UiO, HF-UiO, Sparebanken-1 Nord-Norge, Norsk Ordbok 2014, Danmark: Forskningsrådet for Kultur og Kommunikation, Sverige: Vetenskapsrådet og Riksbankens Jubileumsfond. Island: Háskóli Íslands. Dessuten: NordForsk og NOS-HS.
Nordisk dialektkorpus er både et forskningsverktøy som vil ligge der til bruk for interesserte språkforskere for all fremtid, men også et produkt som er basert på forskning og kunnskap av fagfolk. Slik sett er det både et mål og et middel.
Korpuset kan brukes til forskning av alle slag. For det første er det selvsagt svært nyttig for dem som er interessert i geografisk variasjon, men også variasjon koblet til kjønn, alder, og årstall. I tillegg kan det brukes som en generelt språkkorpus uten tanke på variasjon etter bestemte kriterier. Alle deler av språkvitenskapen kan nyttiggjøre seg korpuset, enten det er fonetikk, fonologi, morfologi, syntaks, leksikografi eller semantikk.
Jeg velger her å vise ett eksempel på hva korpuset kan brukes til. Jeg velger ganske enkelt å søke på pronomenet hun i Norge, med formål å finne ut noe om uttalen rundt i landet. Her er et kart som er generert ut fra dette søket:
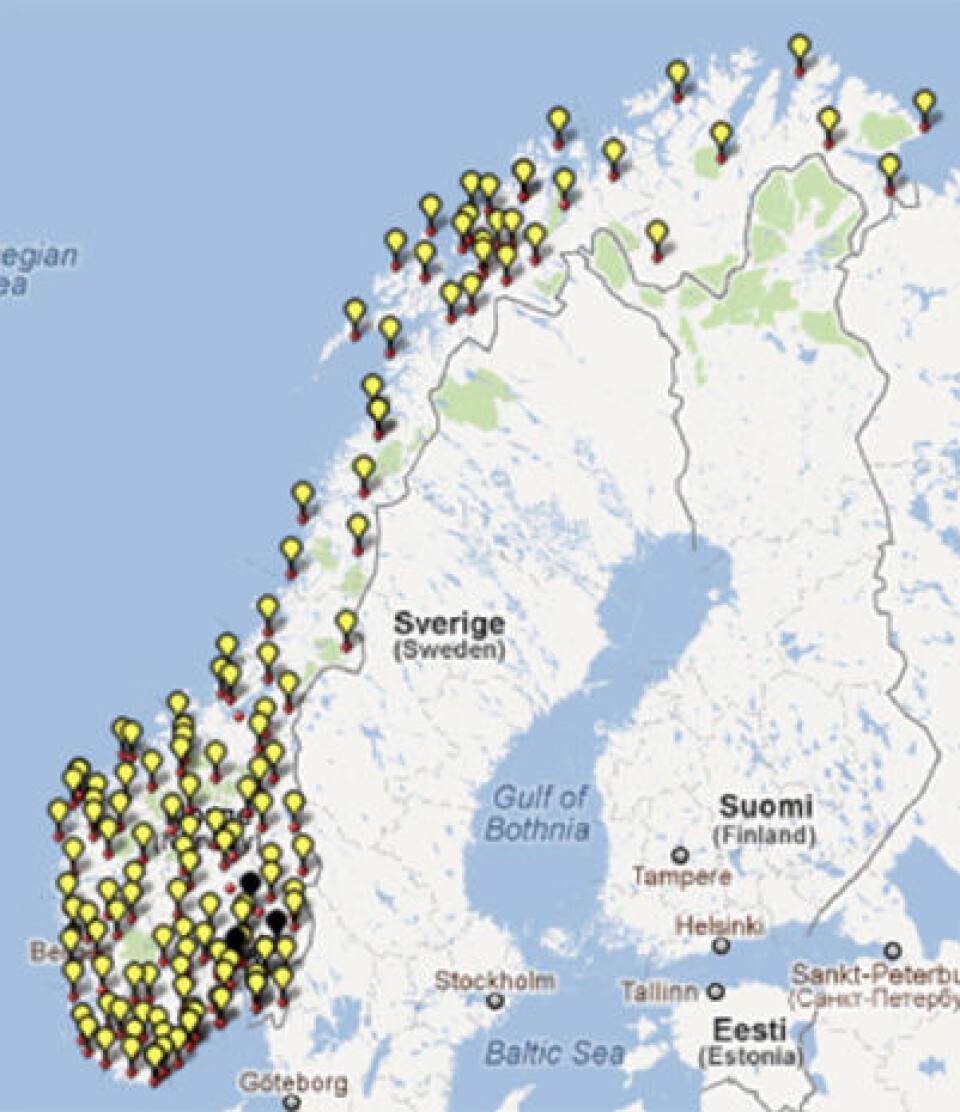
Jeg har ikke valgt ut alle mulige uttaler her, men kun ho og hun. Det er kanskje overraskende for mange at ho (de gule markørene) er i så overveldende flertall i talemålet til nordmenn, mens hun (de svarte) er begrenset til et lite område i og rundt Oslo. Det er enorme muligheter for ny kunnskap som kan avdekkes med dette korpuset. Slik har korpuset stor språkvitenskapelig og kulturell verdi.
Til slutt må jeg nevne en annen nytteverdi av korpuset: Språkvitenskapelig forskning basert på massiv empiri er en uvurderlig kilde for språkteknologi og taleteknologi. Hva er vitsen med å lage en snakkende robot som kun forstår hunkjønnspronomenet hun, hvis ho (blant flere muligheter) er det som brukes av folk flest?
Hvem kan bruke korpuset? Det kan hvem som helst, til små og store forskningsformål. Her er lenka til korpusets hjemmeside.
Korpuset har vært omtalt av flere i forbindelse med lanseringen i 2011:
Forskning.no (Blogg av Øystein Alexander Vangsnes)
Forskerforum, 2. januar 2012 (s. 26 i pdf-utgaven)
Språkteigen:
- Om RU i stedet for DU. NRK Språkteigen 7. januar 2012.
- Om Nordisk dialektkorpus. NRK Språkteigen 1. januar 2012.