Fotball-EM-overrasket?
Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.
Av seniorforsker Anders Løland og sjefsforsker Magne Aldrin ved Norsk Regnesentral
Norsk Regnesentrals fotball-EM-modell hadde før mesterskapet Spania som en knapp EM-favoritt, selv om Tyskland var anslått å være det sterkeste laget, http://www.nrk.no/sport/fotball/em/1.8184796. Nederland var også en stor favoritt, og sannsynligheten var nesten 60% for seier for en av tre store.
Siden da har mye endret seg. Figuren viser utviklingen i vinnersannsynlighet hittil i EM. Legg merke til Russlands vekst og tragiske sorti. Modellen ble som vi andre overrasket over tapet for Hellas.
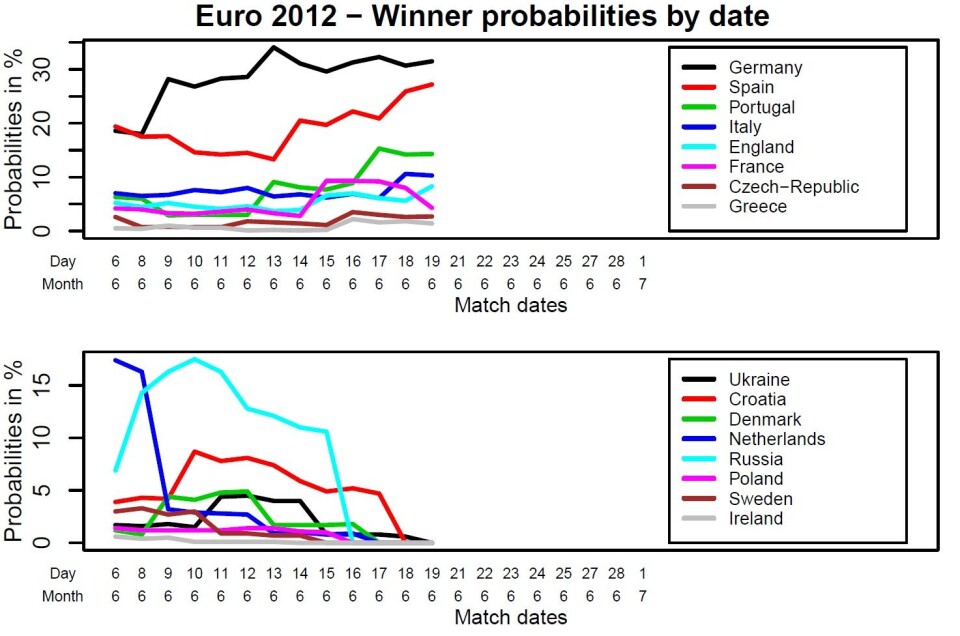
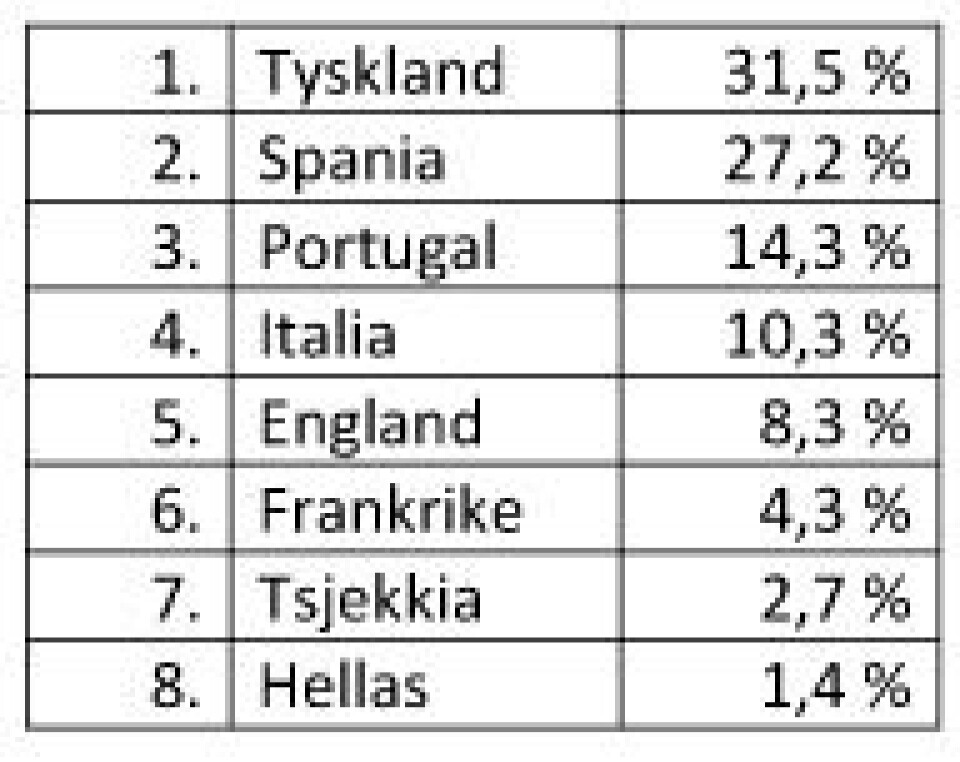
Med kun åtte lag igjen kan vi utrope Tyskland til den mest sannsynlige vinneren, og sjansen er nesten 60% for at enten Tyskland eller Spania lykkes i år. Tyskland og Spania vurderes som omtrent like gode, men Tyskland har størst sjanse til semi-finale-spill siden de møter relativt svake Hellas i kvartfinalen. Her er de åtte gjenværende lagenes vinnersjanser:
Modellen måtte læres opp
Før EM lot vi tolv av NRKs fotballentusiaster tippe tre like sannsynlige utfall i gruppespills- og faktiske kamper. Før EM baserte modellen vår seg kun på disse fotballentusiastene. Alternativt kunne vi ha lært opp modellen på tidligere kamper eller FIFA-rankingen, men det er mye som taler for at det ikke er en god idé. Treningskamper er treningskamper (tenk på mesterskapslag som Tyskland og Italia), det for lenge siden forrige mesterskap og FIFA-rankingen er litt tvilsom.
Vår tilnærming ligner på en såkalt bayesiansk analyse, hvor en lar både data og annen kunnskap telle. Alle fag har sine fremmedord, og de sentrale her er a priori og aposteriori:
- a priori: tips fra NRKs fotballentusiaster
- a posteriori: en kombinasjon av faktiske kamper og fotballentusiastenes tips
Hadde EM fortsatt uendelig lenge ville fotballentusiastenes fotballtips til slutt ikke betydd noe.
Til tider har dette vært en kontroversiell metode, og en skiller gjerne mellom bayesianere (data + annen kunnskap) og frekventister (data alene).
Som den amerikanske statistikeren Brian Efron har sagt: “The 250-year debate between Bayesians and frequentists is unusual among philosophical arguments in actually having important practical consequences.”
Så når brukes bayesiansk analyse?
Tenk deg at du vil analysere om et nytt legemiddel har mer enn placeboeffekt. Da er du neppe interessert i en analyse hvor en uavhengig(?) ekspert trekker inn sin erfaring med produktet.
Et godt eksempel på naturlige bayesianere er fra oljebransjen: Her er det litt grove data (brønndata samt seismikk), som kanskje tilsvarer å finne ut hvordan menneskekroppen fungerer fra tåkete røngtenbilder og et par nålestikk. Heldigvis vet geologene en god del om hvordan det kan se ut under havet. Denne olje-/gasskombinasjonen av data og ekspertkunnskap jobber vi med på NR, og i denne bransjen nytter det ikke å være frekventist.
For tiden er heldigvis ikke skyttergravene mellom bayesianerne og frekventistene så dype som de har vært før.
Tilbake til det viktigste: Følg oss på em.nr.no, og måtte den beste vinne!