

«Nei, Siri, det kan du ikke si!»

Ordene “etikk” og “AI” kan fremkalle dystre fremtidsscenarioer der roboter ikke lenger føler seg forpliktet av menneskelige regler og verdier, og tar over verden. Slike tankeeksperimenter egner seg godt til filosofiske diskusjoner, men de kan også ta fokuset vekk fra de reelle etiske utfordringene som oppstår med dagens AI-baserte systemer. En kjent AI-forsker, Pedro Domingos, oppsummerte dette i sin bok “The Master Algorithm” (2015): “People are afraid that computers could become smart and take over our world. The real problem is that they are stupid and have already taken over the world.”
Jeg forsker på den delen av AI som heter språkteknologi, altså utvikling av datamodeller som behandler språk i en eller annen form. Språkteknologi er integrert i produkter og tjenester vi bruker hver dag — fra stavekontroll til søkemotorer, maskinoversettelse (som Google Translate), talegjenkjenning og virtuelle assistenter (Siri, Alexa, osv.).
Med den økende tilgjengeligheten av disse teknologiene har også flere etiske problemstillinger blitt tydelige. For eksempel benyttes tekstanalyse til overvåkning av individer eller grupper på nettet, samt til manipulering av brukere på sosiale medier. Virtuelle assistenter har blitt kritisert for å oppmuntre til seksuell trakassering. Nylig har også såkalte “deepfakes” vist seg i stand til å forfalske en persons stemme og talemåte på en så realistisk måte at de nesten blir umulig å avdekke.
Dette er viktige problemstillinger, men i dette innlegget vil jeg fokusere på en litt mindre kjent etisk problemstilling, nemlig bias, eller skjevhet på norsk.
Data er ikke nøytrale
Mange tror at AI-modeller er iboende objektive, siden de er baserte på matematiske ligninger som ikke gir rom for fordommer eller forutinntatte meninger. Men AI-modellene må læres opp fra datasett skapt av mennesker, og vil derfor gjenspeile, og noen ganger forsterke, de subjektive oppfatningene mennesker bringer inn. Et automatisert saksbehandlingssystem trent på historiske data fra menneskelige saksbehandlere vil gjenta beslutningene som er observert i datautvalget, selv om de er preget av subjektive meninger og fordommer.
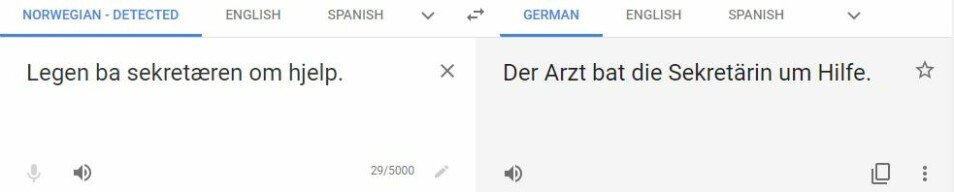
Slike skjevheter forekommer også i språkteknologi. Hvis vi bruker Google Translate til å oversette setningen “ Legen ba sekretæren om hjelp” til tysk får vi som resultat “Der Arzt bat die Sekretärin um Hilfe”, altså med en mannlig lege (i stedet for “die Ärztin”) og en kvinnelig sekretær. Oversettelsesystemer læres nemlig fra store mengder oversatte tekster og gjenskaper språkmønstre og assosiasjoner som finnes i disse samlingene.
Tekstsamlinger (spesielt de som kommer fra sosiale medier) kan inneholde mange slike fordommer og stigma, ikke bare om kjønn men også legning, etnisitet eller kulturell bakgrunn. Ta et annet eksempel på hvordan fordomsfulle ytringer på nettet kan sive inn i språkteknologiske modeller: hvis man skriver “hvorfor er innvandrere ...” i Bings søkefelt, kommer “voldelige” som første forslag til neste ord. Igjen dukker dette forslaget opp på grunn av det underliggende datagrunnlaget (nettsider og spørringer til søkemotoren), hvor setningen forekommer ofte.

Er datautvalget representativt?
Skjevheter kan også ta andre former ved å over- eller underrepresentere ulike befolkningsgrupper i utvalget. Ta for eksempel taledatabaser, som er samlinger av lydopptak skrevet ned ord for ord. Taledatabaser er spesielt nyttige i språkteknologi, blant annet for å trene talegjenkjenningssystemer.
Men å samle inn slike lydopptak er en kostbar affære, og personene som skal tas opp er derfor valgt ut etter visse kriterier. Ofte velger man kun morsmålsbrukere med en tydelig stemme og en relativt “standard” dialekt. Talegjenkjenningssystemer trent på dette grunnlaget vil dermed fungere bedre på noen deler av befolkningen (for eksempel spreke mennesker med østlandsdialekt) og verre for andre (for eksempel eldre personer eller innvandrere med utenlandske aksenter). Slike skjevheter kan dermed bidra til å forsterke allerede eksisterende ulikheter.
Dette kan føre til høyst reelle konkrete konsekvenser for en del mennesker. Noen rekrutteringsbyråer har for eksempel begynt å innføre telefonintervjuer som benytter seg av automatisert taleanalyse til å vurdere kandidatenes kommunikasjonsevner. Det er lett å se for seg at slikt system vil ha en tendens til å gi negative vurderinger av kandidater fra språklige minoriteter, siden disse ofte vil være fraværende i systemets datagrunnlag.
Språklig (u)rettferdighet
Lignende skjevheter gjelder også mellom språk. Brorparten av forskningen på språkteknologi har til nå fokusert på et fåtall språk, og først og fremst på engelsk. Modellene er nesten alltid først utviklet og testet på engelskspråklige materiale, og utvikling av modeller for andre språk skjer ofte i etterkant(*). “Ressurssvake” språk (swahili har tilnærmet ingen språklige ressurser, selv om det snakkes av millioner mennesker i Afrika sør for Sahara) og deres brukere kommer svært dårlig ut av det — både på grunn av mangel på tilgang til teknologi, men også mangel på kulturell anerkjennelse, siden språk er så intimt knyttet til vår sosiokulturelle identitet.
Med andre ord: vi har en lang vei å gå før etikken gjennomsyrer hele denne teknologien. Men det finnes gode nyheter: Forskere og utviklere i språkteknologi har blitt mye mer bevisst på disse etiske utfordringene, og på faglige konferanser florerer det i dag av artikler som tar for seg etiske betraktninger knyttet til blant annet personvern, skjevheter i datautvalget eller mangel på språklig mangfold. Det er lite tvil om at etikk kommer til å spille en viktig rolle i fagfeltet fremover!
*Dominansen av engelsk i språkteknologi har påvirket fagets utvikling i veldig stor grad. De fleste språkmodellene som brukes i dag fokuserer f.eks. sterkt på ordstilling og tar lite hensyn til morfologi (altså ordbygging), noe som kan forklares av at engelsk nesten ikke har morfologi lenger. Hadde finsk blitt verdens globale språk i stedet for engelsk hadde historien vært helt annerledes.