
Arbeidet med 1875-tellinga
Skrevet av Tor-Ivar Krogsæter
På Registreringssentral for historiske data (RHD) i Tromsø, har vi i lengre tid jobbet med å klargjøre folketellingene fra 1800-tallet og begynnelsen av 1900-tallet til bruk for både forskere og folk flest. Vi er en håndfull forskere, ingeniører og assistenter som jobber med dette daglig, der vi bearbeider og korrigerer transkripsjonsarbeidet gjort hovedsakelig av slektsinteresserte «over dammen». Det sier seg selv at det er en enorm besparing i å få de mange årsverkene gjort av frivillige, men opprettingsarbeidet vi blir sittende med, har vist seg å være mer omfattende enn først antatt.
Det daglige arbeidet på RHD

Våren 2015 lyste RHD ut ei halv stilling som vitenskapelig assistent, og jeg var så heldig at jeg fikk tilslag på den. Siden da har jeg jobbet tett med 1875-tellinga, og fått en stadig bedre, intuitiv innsikt i samfunnsforhold på den tida. Til transkripsjonen av materialet benytter vi oss både av norske og amerikanske frivillige. De norske frivillige er organisert gjennom Slekt og Data (tidligere DIS-Norge), og de amerikanske i The Church of Jesus Christ of Latter-day Saints (LDS), som er lokalisert i Minnesota (MN) og Salt Lake City (UT). På den ene sida besørger denne arbeidsmetoden for store besparelser; på den andre sida hadde veldig mange korrigeringer formodentlig vært unngått dersom transkripsjonene utelukkende hadde vært gjort av personer med solide norskkunnskaper.
Noen eksempler på transkripsjonsfeil
Likevel, problemene man må forvente – når man i så stor grad belager seg på frivillig arbeid – merkes tidvis tydelig. Et par ganger har jeg holdt en liten matpausespørrekonkurranse for kollegene mine, der de har fått forsøkt å gjette hva feiltranskripsjonene jeg har jobbet med har vist seg å egentlig skulle være. Et lite knippe av disse vises i lista nedenfor, med løsningene lagt inn skjult:
- Mor og datter hadde samme levebrød, visstnok «Ernærer Oiz ved Dovning og Spindn». Hva gjorde de egentlig? (Hint: De var ikke dovne …)
(Transkripsjon fra kommune 0540, krets 2, liste 4, person 005.) - I dette tilfellet kunne det se ut som en transkribør hadde satt inn sykdom i feil felt, for mannen var belemret med «Logeblem», og det var så ille at han måtte «Forsørges Of Fattigovsenet« (sīc). Hvilken «plage» var det egentlig vedkommende hadde?
(0540.4.30.006) - En herremann var «alencieskalilarer». Feiltolkninga kan forstås når man ser originalen. Hvilket standsmessig yrke hadde denne utdannede herren?
(0938.6.21.1)
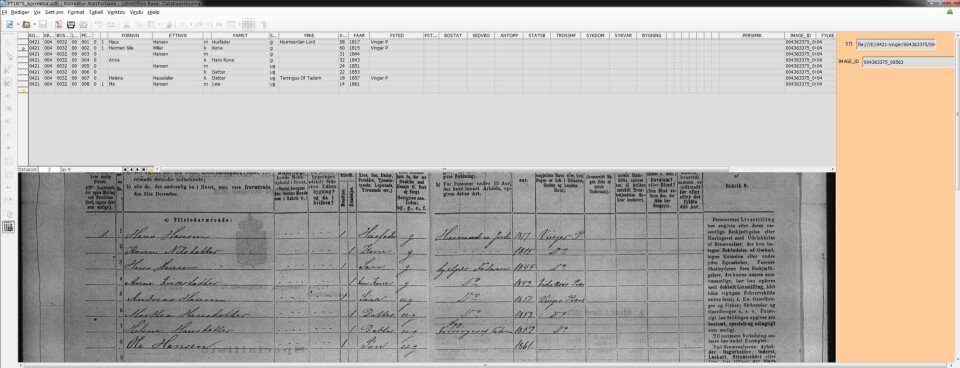
<p>Et typisk eksempel på hvilke transkripsjonsproblem som kan dukke opp. Merk at ikke bare er det transkriberte feil, men store mengder data mangler også. Det er i utgangspunktet det feiltranskriberte som gjør at vi oppdager at slike data mangler, ikke motsatt. Vi har riktignok fått laget noen spørringer som kontrollerer for opplysninger som burde være til stede, men ikke er det, men når det er små familier der for eksempel yrke (<abbr title="Forklaringstegnet, dvs. «altså»">ɔ</abbr>: «Livsstilling») ikke er ført på andre enn familiefaren (som ikke er uvanlig), er det faktisk ikke mulig for oss med de nåværende metodene å identifisere disse.</p>
<p>Bilde fra 1875-folketellinga, Vinger kommune, krets 4, bosted 32.</p>
Noen ganger – som «Kurmager»-en som egentlig var «Kurvmager» – er feilene sannsynligvis tastefeil, ikke feiltolkning. Verre er det når man virkelig skulle tro transkribøren har gjettet vilt, varierende fra rent uskyldig til fullstendig på bærtur:
- En person hadde yrket «Kensesvist»; dette var egentlig …?
(0545.001.36.?) - En annen var ført som «Floes med Seiresæiet», men egentlig var han …?
(0545.001.32.011) - Denne karen hadde ikke det yrket man ved første øyekast skulle tro; han var transkribert som «Leensbygdens Metros». Hvor jobbet han egentlig?
(0545.001.55.102) - Til slutt en mann ført opp som «Tamburg Gaard», tilsynelatende et stedsnavn, noe det viste seg at det ikke var. Hva var han?
(0540.1a.49.004)
Årsaker og løsninger
Transkripsjonsproblemer som følge av at transkribøren ikke behersker tekstmaterialets språk er ikke noe nytt.* I Canada ble det innledet et eget prosjekt for å renske opp i transkripsjonen av fransk-kanadiske navn gjort av anglofone transkribører.* Nettopp denne typen feil er årsaken til at jeg i korrekturarbeidet har valgt å korrigere ikke bare det de enkelte spørringene har forespurt* – som man må anta hadde vært mest effektivt – men har rettet opp samtlige feil som måtte dukke opp i individopplysningene til husholdet. Det sier seg selv at arbeidet har tatt lang tid. På gode dager har jeg på det meste kommet meg gjennom over 200 lister;* når det har vært mange problemer med transkripsjonene, har det kunnet gått så sakte som bare 70–80 lister per dag; og til vanlig ligger jeg i området 120–150 lister per dag.
For å få økt antall lister per dag, har ikt-ansvarlige Trygve Andersen og jeg jobbet tett for å få laget bedre spørringer. Veldig mange feil har blitt luket ut ved å kjøre update-spørringer på datasettene, f.eks. ved at de mange variantene av patronymikon-endelser har blitt standardisert til ‑sen og ‑datter. Dette har noen ulemper ved seg: I noen kommuner er særlig ‑dotter i stedet for ‑datter vanligere (det er sjeldnere å se ‑son for ‑sen); dessuten vet vi at dette betyr at poster som kan inneholde små (men vanligvis ubetydelige) transkripsjonsfeil, faller ut fordi det ikke lenger er noe ved dem som kan fanges av filtrene våre.* De som bruker dataene som legges ut bør være oppmerksom på dette når de ser gjennom navnelistene: Dersom man kommer til områder der «‑dotter» sporadisk opptrer, er det mest sannsynlig dette som er det riktige. Det er dessuten sannsynlig at det er flere som har slike patronymikonendelser, ettersom vi kun får filtrert ut listene med feil i.
For å bøte på dette problemet har Andersen laget ei frekvensbasert ordbok over livsstillinger (yrker), som gjør at vi får filtrert ut de listene vi ikke greier å finne med select kjørt særlig på livsstilling.* Ordboka er laget ved å hente ord som har en frekvens på mindre enn 10 fra det forespurte feltet fra alle husstandene i fylket. Når vi så kjører select-spørringa, får vi listet alle som potensielt har feil i yrkesbeskrivelsen sin; erfaringsmessig er det nokså sannsynlig at det også er andre feil i transkripsjonen av disse husstandene. Ordboka er laget ved å hente ord som har en frekvens på mindre enn 10 fra det forespurte feltet fra alle husstandene i fylket. Når vi så kjører select-spørringa, får vi listet alle som potensielt har feil i yrkesbeskrivelsen sin; erfaringsmessig er det nokså sannsynlig at det også er andre feil i transkripsjonen av disse husstandene.
Lærdom
Det er med andre ord to viktige ting å lære av dette: For det første er det forskjell på å jobbe på mikro- og makronivå. I førstnevnte tilfelle er det viktig at man ikke glemmer å gå til kilden, for feil kan ha skjedd. I sistnevnte tilfelle kan man få mye hjelp av å bruke ulike metoder for å gjøre ei statistisk utjevning av feilene som måtte ha oppstått. Man ser også at det er viktig at historikeren/demografen har god kunnskap om studieobjektet satt i kontekst, da det gjør vedkommende langt bedre rustet til å tolke opplysningene – og særlig avvikene som måtte dukke opp – på en bedre måte. Når disse kildetypene så kan sammenlignes, får man et sterkt redskap for å gjøre brede sammenligninger.* Men å ha historiefaglig innsikt er ikke nok når man arbeider med slikt materiale; det er i tillegg nødvendig at man har en grunnleggende innsikt i statistikk.
Noen avsluttende betraktninger

Å komme inn i dette som fersk, nyutdannet historiker har gitt meg anledning til å arbeide med nok et prosjekt om samfunnets avvikere. Ved å gå dypt inn i kildematerialet slik korrekturarbeidet tillater, har jeg fått den nødvendige innsikten som trengs for å kunne utforme relevante arbeidshypoteser. Resultatet av det arbeidet jeg nå skal gyve løs på, blir presentert i form av en artikkel mot årsslutt, der jeg skal se om det lar seg gjøre å studere folks forhold til utskuddene, så som de mentalt syke og de innsatte – i første omgang de sistnevnte.
For bare et par generasjoner siden kunne slike spørsmål ikke besvares med den kildetilgangen man hadde; dessuten var interessen for å undersøke uvanlige (altså særlig kjønnsrelaterte) spørsmål nokså begrenset, men den feministiske bølgens fremmarsj innen akademia, gjorde forskerverden oppmerksom på at det fantes mangfoldige interessante og krevende spørsmål ingen hadde brydd seg med å undersøke. Nå har vi både viljen og evnen til å undersøke slike tidligere «alternative» problemstillinger. Tidligere tiders teknologiske begrensninger kan i dag stort sett ignoreres, langt flere kan bidra enn før, og tilgangen på kildematerialet i form av digitale bilder og transkriberte, søkbare data, gir oss muligheta til en helt ny innsikt i hvordan folk forholdt seg til det abnormale.
Referanser og kommentarer
Transkripsjonsproblemer og morsmål: Problemer som følge av transkripsjonsfeil er i det hele tatt velkjent. Inwood og Roberts nevner det i oversiktsartikkelen sin om longitudinelle studier, der de forteller at «It may be difficult to match individuals with widely shared characteristics (e.g. the surname of Smith) […]. In practice the decision about matching individuals is inexact and probabilistic because of variations in the way names were recorded, age heaping, and errors in the original enumeration and transcribing the handwritten sources into a machine-readable format.» (Inwood og Roberts, Longitudinal Studies of Human Growth and Health: A Review of Recent Historical Research, Journal of Economic Surveys, 2010, bd. 24 (5): 813) Se også n. 39 s. 8. Tilbake til teksten.
Canadas anglofone transkribører: Roberts m.fl., 2003: n. 8 s. 87. Disse problemene ble også tatt opp blant annet av Siegfried Gruber under åpningsforedraget under sommerskolen i historisk demografi og statistikk i Cluj-Napoca juni 2016 (se nedenfor). Tilbake til teksten.
Siegfried Gruber: Dette ble fortalt om på sommerskolen i historisk demografi, holdt i Cluj-Napoca 13.–19. juni 2016. (Disse refereres heretter til som «Forelesningsnotater Krogsæter» med foredragsholderen og foredragsdato nevnt.) Full referanse: Forelesningsnotater fra sommerskolen i Cluj-Napoca, 13.–19. juni 2016, EHPS-Net International Summer School in Historical Demography – Introductory course: Fourth Edition, Cluj-Napoca, Romania 2016: forelesning med Siegfried Gruber 13. juni 2016. Han påpekte at selv om behandling av store data ikke lenger er noe teknisk problem, er det et problem hvordan disse dataene håndteres: For å spare penger, sendes dataene til lavkostland for transkripsjon; dette fører til problemer nettopp som jeg har beskrevet i det foregående. Tilbake til forrige note.
Spørringene: Hver enkelt spørring har etterspurt en bestemt type feil, som feil i etternavn, feil i fornavn, feil i sykdom, feil i bosted – alle disse ulike spørringer. Tilbake til teksten.
Liste: Et ark fra folketellinga med alle husstandens personer listet opp med respektive data. For eksempel, se under skjema A på RHDs hjemmeside: Holtet og Andersen, [Instruks og skjema til] Folketelling 1875, Tromsø, hentet 18.07.2016. Tilbake til teksten.
Feiltranskripsjoner: Se «Leensbygdens Metros» og «Tamburg Gaard». Tilbake til teksten.
Frekvensbasert ordbok: I databasen vår har feltet etiketten yrke, som tilsvarer kildedokumentenes felt «Livsstilling». Man kunne ha brukt denne metoden på andre felt også – som f.eks. i feltet «bygning»* – men problemet er at de øvrige feltene ofte inneholder ord som ikke har noen reell betydning for innholdet,† så inntil videre anser vi det som lite tjenlig. Tilbake til teksten.
* Tilsvarende kildenes rubrikk 5: «Havde nogen af Beboerne sin Bolig (Natteophold) i en særskilt fra Hovedbygningen adskildt Side- eller Udhusbygning? og da i hvilken?» Tilbake til noten.
† Mens feltet for livsstilling gjerne har utfyllende informasjon om hva vedkommende gjorde for å tjene til livsoppholdet, inneholder feltet for bygning – hvis det har tilleggsopplysninger utenom byggets navn – vanligvis bare tilleggsopplysninger om hvor bygget stod. Det finnes dog noen hederlige unntak: Live Fingarsdatters familie hadde «:Bolig i en Stald hvori Ovn og Vindue» – om ikke annet, gir det i hvert fall et historisk perspektiv til studentboligdebatten. Tilbake til noten.
Historisk innsikt og kildekobling: Forelesningsnotater Krogsæter: forelesning med Siegfried Gruber 13. juni 2016. Et glimrende eksempel på kontekstens betydning for riktig tolkning av resultatene, er i Fyson og Fenchel, Prison registers, their possibilities and their pitfalls: the case of local prisons in nineteenth-century Quebec, The History of the family, 2015, bd. 20 (2): 175–8. Tilbake til teksten.
Løsning: De «Ernærer sig ved Vævning og Spindn.» Tilbake til teksten.
Løsning: Vedkommende var «Lægdslem». I legdesystemet ble et knippe gårder gitt samfunnsoppgaver som å stille soldater eller besørge underhold av fattige; et legdslem var med andre ord en fattig som fikk kost og losji dekt av gården vedkommende var bosatt på. Etter gammel lov skulle fattigansvaret gå på omgang mellom gårdene, men etter hvert som pengeøkonomien vant gjennom ble dette ble fortrengt av anbudsløsninger. Se Imsen og Winge (red.), Kultur og samfunn ca. 1500–ca. 1800, Norsk historisk leksikon, 2. utg., 1999: «Legd»; og Store norske leksikon (nettutgaven): «legd». Tilbake til teksten.
Løsning: «Almueskolelærer». Tilbake til teksten.
Løsning: «Pensionist». Tilbake til teksten.
Løsning: «Elev ved Seminariet», altså lærerskolen. Tilbake til teksten.
Løsning: «Leensbygdens Meieri». Det er nettopp denne typen feiltranskripsjoner som er problematiske, for personen hadde lett blitt kodet som matros, når han altså i stedet var «meieriarbeider». Tilbake til teksten.
Løsning: «Tambur og Gaardsarbeider». Som over er dette et eksempel på den type transkripsjonsfeil som er vanskelig å oppdage, ettersom ordet som opprinnelig stod i det transkriberte – Gaard – er et vanlig ord som derfor ikke hadde blitt plukket opp av filtrene våre, så som ordbokfilteret som jeg tar opp litt senere i teksten. Tilbake til teksten.