
Nå har polartorsken fått QR-kode
Mens Nansen var på tokt i arktiske farvann, forgikk forskningen ved hjelp av enkle verktøy for observasjoner. Observasjonene ble skrevet ned i loggbøker, som så ga grunnlaget for oppdagelsene som ble gjort.
I dagens forsking er loggboken fortsatt et viktig verktøy for en forsker, men det er ikke lengre slik at flesteparten av observasjonene blir gjort manuelt.
Ta for eksempel toktet jeg er med på nå, et av toktene i prosjektet «Arven etter Nansen», som skal kartlegge biologiske, kjemiske, geologiske og fysiske forhold nordøst for Svalbard. Her samler forskerne innen store mengder prøver, i form av for eksempel vev og blod fra bunnlevende dyr, dyre- og planteplankton, vannprøver, virusprøver, celler og iskjerner. I tillegg samles det inn data fra instrumenter på båten, som for eksempel ekkolodd, sjøvannstemperatur, saltinnhold og værdata. Alle disse prøvene og dataene skal gjennom prosjektet gjøres tilgjengelig for alle forskerne i «Arven etter Nansen». Senere skal de publiseres i en åpen database.
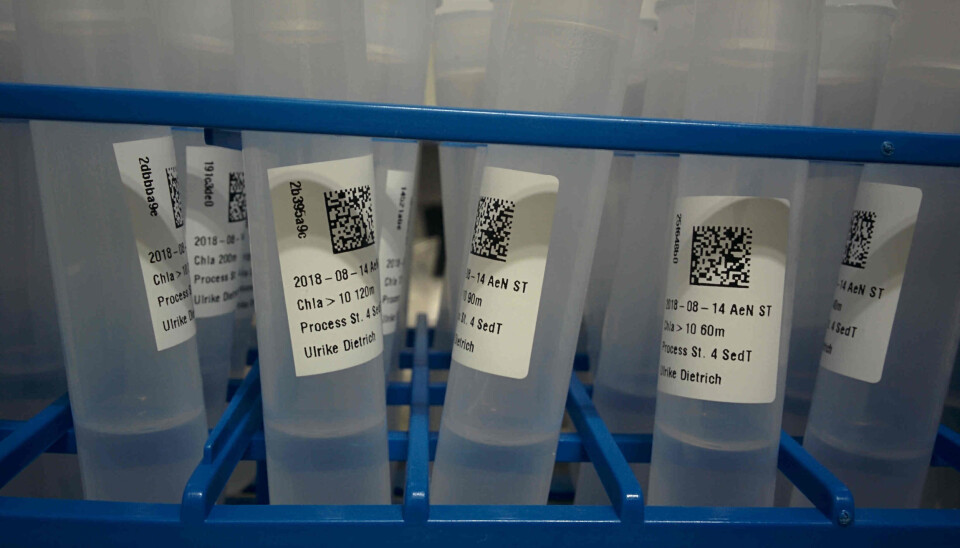
Forskerne i prosjektet kommer fra mange forskjellige institusjoner. For at vi skal få delingen har vi innført et merkesystem ombord som er basert på unike IDer i form av en QR kode (mosaikkode). Alle prøvene og dataene ombord får en ID som sammen med informasjon om prøvene blir logget i en database.

I etterkant av toktet vil forskerne og andre kunne gå inn på databasen som vil ligge hos SIOS (Svalbard Integrated Arctic Earth Observing System) å søke opp enkelte prøver, men også få oversikt over dette og senere tokt i sin helhet. Denne databasen er under utvikling og vil komme på nettet en gang etter toktet. Siden «Arven etter Nansen» tilstreber mest mulig deling, og å gjøre det tilgjengelig for allmenheten, ligger verktøyene vi har utviklet tilgjengelig gjennom Github. Dette muliggjør at andre kan ta i bruk et lignende system.
Når jeg sitter her nord for 80 grader, er det på en båt som har datasystemer og servere tilsvarende det en ville finne i en middels stor bedrift. Dette medfører at vi kan samle inn store datamengder per dag, opp mot 1 TB daglig og behandle dem på en måte som er grensesprengende. Disse dataene må behandles og analyseres før de kan publiseres, noe som er oppgaven til forskerne og ingeniørene i prosjektet. Håpet er at dataene vi samler inn i dette prosjektet ikke bare vil komme forskerne og allmenheten til gode de seks årene prosjektet varer, men også i fremtiden, gjennom gode rutiner for å lagre informasjon om prøver og data, såkalt metadata.