

La datamaskina sjekke oljebrønnen!
Det kan være krevende å tolke ultralydmålingene som brukes til å sjekke om oljebrønner er tette. Vi har funnet ut hvordan datamaskiner kan hjelpe til med tolkningsjobben.

Når man bygger en oljebrønn vil man for all del at den ikke skal kunne lekke. Hvis den gjør det, er det ikke bare farlig for miljøet, men også arbeiderne på plattformen. For å unngå dette, klemmer oljeselskapene sement ned i brønnen. Denne sementen skal ligge mellom bergveggen i borehullet og stålrørene som plasseres der, for å stoppe all uønsket væskestrømning.
Brønnloggtolkning
Likevel holder det ikke å bare klemme ned sementen og håpe på det beste. Oljeselskapene er veldig nøye med å teste at den har lagt seg slik den skal. Som jeg skrev her i fjor, gjøres mye av denne testinga, som vanligvis kalles brønnlogging, med ultralyd.
Men brønnlogging gir ikke et perfekt bilde av nøyaktig hva som er nede i brønnen, og det er ikke alltid opplagt for enhver hva loggene sier. Derfor må eksperter innenfor logging tolke loggene for å finne ut av hva som er der nede.
Dette er ikke alltid en enkel oppgave. Loggene er komplekse; det gjøres mange forskjellige målinger, og alle målingene har sine usikkerhetskilder. For å komme fram til en god forståelse av hva som er nede i brønnen, må loggtolkerne derfor ta i bruk mye forskjellig informasjon, blant annet:
Brønnintegritet og integritetsmåling
To forskjellige tverrsnitt av en bit av en frisk oljebrønn, nær toppen av sementen. Illustrasjon: Erlend Magnus Viggen/NTNU
En oljebrønn er i utgangspunktet et hull boret gjennom bakken, fra overflata ned til et reservoar med olje og/eller gass. I hullet plasseres stålrør for å hindre at hullet kollapser, og for å bære olje og gass kontrollert fra reservoaret til overflata.
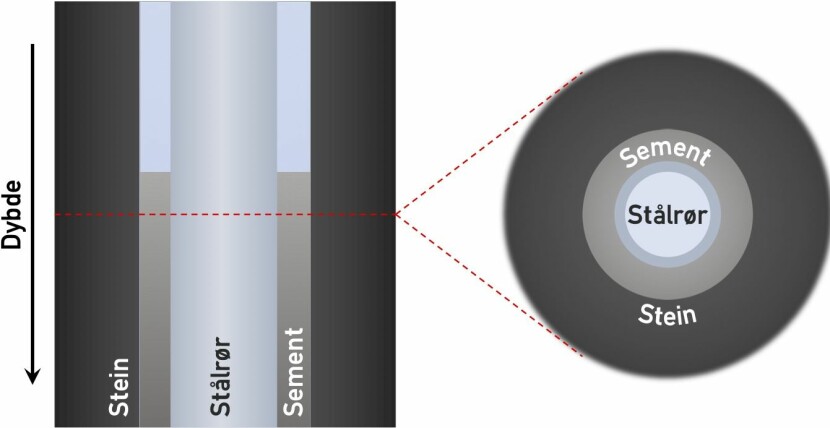
Hvis sementen som deretter klemmes ned i brønnen plasserer seg som ønsket, vil den dekke og dermed forsegle hele brønnens tverrsnitt mellom røret og steinveggen, slik figuren viser. Brønnen er da tett, og denne tettheten kaller vi brønnintegritet.
Ultralydmålingene som brukes til å kontrollere brønnintegriteten består typisk av å skyte en ultralydpuls mot et punkt på den indre veggen av stålrøret og analysere ekkoet som kommer tilbake. Denne analysen gir oss blant annet et estimat av hva som er bak røret.
Disse punktmålingene gjøres i et regelmessig rutenett av punkter, f.eks. med 5° avstand mellom punktene i horisontal retning og 3 tommers avstand i dybderetning. Dermed kan vi bruke resultatene av målingene til å lage “kart” av røret og hva som er bak.
- Historien til brønnen. Denne kan, for eksempel, fortelle hvor mye sement som ble klemt ned, og hvor i brønnen de kan forvente å finne sementen.
- Deres forståelse av hvordan brønner bygges og kan utvikle seg. For eksempel kan noen steintyper krype inn mot stålrøret og til slutt klemme rundt det. (Dette kan faktisk være positivt, da steinen kan bidra til å holde brønnen tett.)
- Deres forståelse av fysikken og dataanalysen som underligger hver type måling.
Dette er en krevende jobb, altså, som tolkerne selvfølgelig ikke har uendelig med tid på seg til å gjøre. Det er dermed kanskje ikke overraskende at to loggtolkere iblant kan se på de samme målingsresultatene og dra litt forskjellige slutninger. Derfor jobber gjerne tolkerne i team, for å sammen kunne diskutere seg fram til en riktigere forståelse, men dette krever selvfølgelig også mer tid.

Automatisk brønnloggtolkning
For å hjelpe loggtolkerne i jobben sin, har vi i CIUS forsket på automatisk brønnloggtolkning. Tanken vår er at loggedataene, altså resultatene av målingene i brønnen, kan gis rett til en datamaskin som kommer fram til en tolkning på flekken.
Denne automatiske tolkningen kan nok ikke erstatte menneskelig tolkning, men den kan brukes som et utgangspunkt. Hvis datamaskinen er flink, vil tolkningen allerede være ganske god. Det vil spare loggtolkerne for en del arbeid, og lar dem fokusere på de mer komplekse områdene av loggen.
Så hvordan lærer man datamaskinen å tolke brønnloggdata? Den klassiske framgangsmåten hadde vært å skrive et dataprogram som gjenskaper beslutningsprosessen til en ekspert innenfor brønnloggtolkning. Men denne beslutningsprosessen er basert på veldig kompleks og sammensatt kunnskap, og det er i tillegg et veldig stort spenn av situasjoner tolkere kan bli bedt om å se på. Å implementere denne beslutningsprosessen i et dataprogram som kan håndtere alle mulige situasjoner er en enorm jobb – et evighetsprosjekt, nesten.
Derfor bruker vi en annen teknikk, nemlig maskinlæring. Denne teknikken baserer seg på at vi har en dataalgoritme som kan trenes opp. Ved å vise algoritmen forskjellig brønnloggdata med en tolkningsfasit utarbeidet av eksperter, vil den selv lære seg hvordan eksperter tolker forskjellige typer data.
Hvis vi har gjennomført denne treninga på en god måte, vil den trente algoritmen være i stand til å komme fram til rimelige tolkninger av data den ikke har sett før – i hvert fall så lenge denne dataen ligner på data den så under treninga.

Så, hvor bra funker det?
Hvor riktige er tolkningene som algoritmen gjør? Dette er strengt tatt et ubesvarlig spørsmål. Vi har ingen “ground truth”, ingen 100% sikre svar på hva som er nede i brønnen. Målingene forteller oss mye, men tenk på det – hvis målingene hadde åpenlyst og utvetydig fortalt oss alt om hva som er nede i brønnen, ville ikke brønnloggtolkning vært nødvendig i utgangspunktet.
Men det vi kan måle er hvor bra algoritmen gjør det vi trente den til, nemlig å se på brønnlogger den ikke har sett før og dra samme slutninger som ekspertene. Litt forenklet sagt, ser vi et samsvar på 87–89% mellom algoritmens tolkning og ekspertenes referansetolkninger.
Så, er det mulig å få til enda bedre resultater? Det er det nok, men vi kommer nok aldri helt opp til 100%, av en enkel grunn: Som jeg nevnte i sted, er ikke ekspertene alltid helt enige med hverandre. Det én ekspert kan vurdere som “middels” sementering kan en annen ekspert vurdere som “dårlig”, for eksempel. Tolkningene som vi brukte som fasit når vi trente og testet algoritmen er utarbeidet av mange forskjellige eksperter. Selv om disse ekspertene er del av et team, er ikke tolkningene helt internt konsistente.
Dette betyr to ting. Den ene er at algoritmen kan bli forvirret under trening når lignende situasjoner har forskjellig fasit. Den andre er at algoritmens svar regnes som feil under testing hvis testfasiten sier noe annet enn det treningsfasiten(e) gjorde for samme type situasjon. Det finnes derfor altså et tak for hvor bra samsvaret kan bli, som er knyttet til hvor enige ekspertene er med hverandre. Jo mer enige de kan være, jo høyere er taket.
Detaljer, detaljer…
Det du nå har lest er et kort og forenklet sammendrag av en lang vitenskapelig artikkel, og jeg har selvfølgelig feiet mange detaljer under teppet. Hvis du vil vite litt mer, har jeg også skrevet et engelsk sammendrag på bloggen min med noen flere tekniske detaljer. Og hvis du vil vite mye mer kan du alltids gå rett til artikkelen, som er fritt tilgjengelig for nedlasting for alle og enhver.