
Hvorfor jeg noen ganger skulle ønske at jeg var lingvist...
Jeg er ph.d.-kandidat innenfor et doktorprogram i språkvitenskap. Men til forskjell fra de andre studentene på dette programmet, har jeg ikke min bakgrunn i lingvistikken.
Jeg kommer fra fagområdet design, og i ph.d.-prosjektet mitt undersøker jeg et stort antall nyere datavisualiseringer på nett fra både et design- og et språkperspektiv.
Å være en del av dette programmet gjør det mulig å diskutere, tenke og stille spørsmål rundt måten lingvister arbeider på, og reflektere over forskjellen mellom fagområdene. Det er nettopp det jeg skal gjøre i denne bloggposten.
Så hva trenger jeg da, hvis jeg skal undersøke eksisterende datavisualiseringer? Nettopp, jeg trenger å etablere en samling av denne type visuelt materiale. Når jeg kikker over til lingvistene, innser jeg, nesten med et stikk av misunnelse, at der i gården finnes det en lang tradisjon for å forske på systematisk innsamlede tekster, såkalte korpora.
Siden 1977 har det vært tilgjengelig et digitalt arkiv med engelske tekster (International Computer Archive of Modern and Medieval English) (Svartvik, 2007, p. 11) som har gjort at lingvister kan starte forskningen sin med et tekstkorpus som allerede eksisterer.
Mye har forandret seg siden 70-tallet, og det har blitt utviklet digre tekstkorpora for forskjellige språk. Bare et lite glimt av hvor store disse er: The Corpus of Contemporary American English (COCA) inneholder mer enn 560 millioner ord hentet fra forskjellige typer tekster. IWeb corpus er enda større, det ble tilgjengelig i mai 2018 og inneholder 14 milliarder ord hentet fra 22 millioner nettsider. Det er ganske imponerende, eller hva?
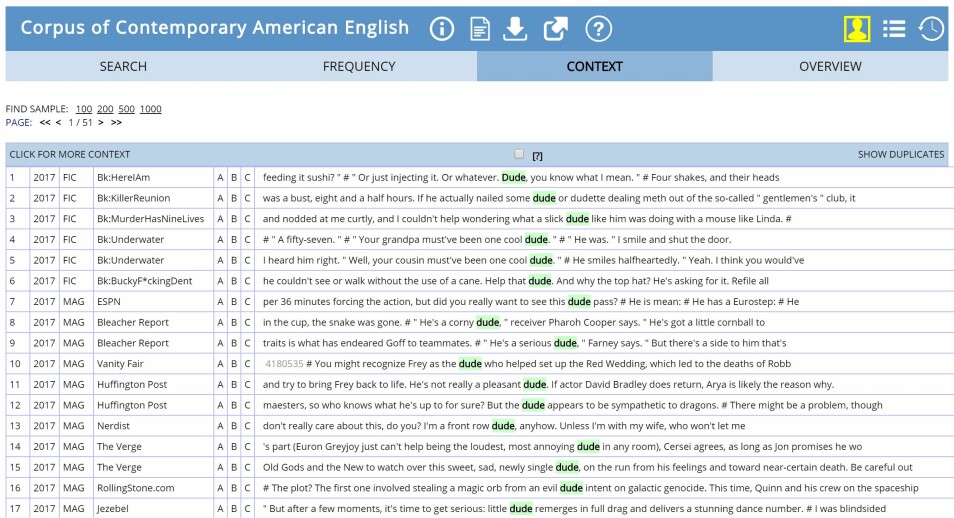
Å sammenligne dette med situasjonen som møter oss som forsker på visuelt materiale – nærmere bestemt oss som forsker på datavisualiseringer – er ganske nedslående. Så vidt jeg har funnet ut, eksisterer det ennå ikke et ferdig arkiv av systematisk innsamlede datavisualiseringer. Du kan finne nettsider med lenker til forskjellige typer datavisualiseringer, som for eksempel www.datavizproject.com, og disse er absolutt gode nok til sitt formål. Men de kan ikke sammenlignes med et tekstkorpus.
Når man finner ut dette, så har man valget: Man kan enten plukke ut noen enkelt-eksempler for hvert enkelt forskningsprosjekt, eller man kan bygge opp sitt eget korpus. Den største ulempen ved å ‘håndplukke’ på denne måten er selvfølgelig at utvalget det resulterer i, ikke er representativt for datavisualisering som fenomen. Uten å gå nærmere inn på hvordan man kan bygge opp et korpus som er spesielt tilpasset et enkelt prosjekt, vil jeg nevne noen av grunnene til hvorfor det ikke finnes tilgjengelig et korpus av datavisualiseringer.
Så hvorfor er det så vanskelig å utvikle et korpus for datavisualiseringer? En grunn kan selvfølgelig være at digitale datavisualiseringer har en relativt kort historie og at det derfor er færre som ønsker å forske på slike samlinger enn innen korpuslingvistikken. Men det finnes andre grunner også. Først og fremst må man faktisk finne datavisualiseringene som svever rundt der i dypet av den store verdensveven. Og hvis vi ønsker å være oppdatert, må denne letingen foregå kontinuerlig. Noen tekstkorpus, som for eksempel COCA eller iWeb, inneholder en bestemt mengde tekst og blir ikke oppdatert. Andre henter jevnlig inn nytt materiale. Et eksempel på slike er Oxford English Corpus der jobben gjøres av en søkerobot som hele tiden, og ut fra forhåndsdefinerte regler, søker etter ny tekst. Skal man forske på hvordan datavisualisering er i ferd med å utvikle seg, vil det være nødvendig at noen utvikler en tilsvarende søkerobot med tilhørende algoritmer.
Når vi da endelig finner noen egnede visualiseringer, trenger vi også å hente dem ut og lagre dem på en trygg måte. Innhold som er tilgjengelig på en bestemt nettadresse, kan når som helst bli endret eller gjort utilgjengelig av opphavspersonene. Dette gjør det nødvendig å ‘laste ned’ materialet på et eller annet tidspunkt, å tidfeste det og lagre enkelte metadata, som navnet på opphavsperson eller publikasjonsdato. Med andre ord er det nødvendig å bli uavhengig av nettsidene hvor datavisualiseringene opprinnelig var publisert. Jeg antar at de av dere som selv har produsert en datavisualisering og publisert den på nettet, nå hører alarmklokkene ringe og spør seg selv: «snakker hun nå om å stjele mitt arbeid, som faktisk er opphavsrettsbeskyttet, ved ganske enkelt å benytte en eller annen automatisk algoritme?»
La meg berolige dere: Det som skjer i korpuslingvistikken er at teksten blir gransket indirekte ved å bruke «spørrespråk, konkordanser (alfabetiske ordlister), analyseprogram og paralleltekster» (Sinclair, 2004, s. 189). For å kunne gjøre dette mulig blir teksten behandlet på spesielle måter før den kan brukes av forskerne. For eksempel blir all formattering slettet, teksten blir delt opp i individuelle ord, utstyrt med merknader og først da blir den gjort tilgjengelig i form av bruddstykker.
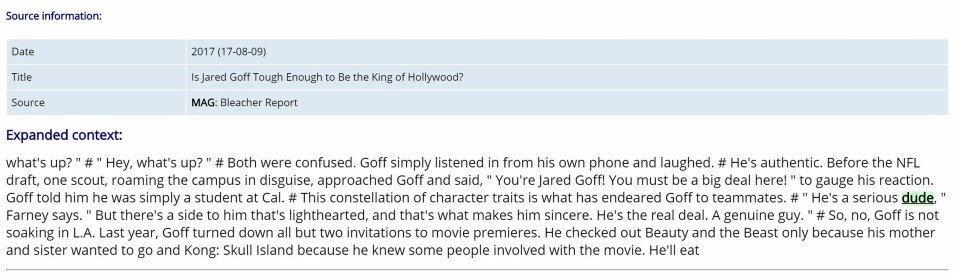
Spørsmålene som da bør stilles er: er det fornuftig å behandle datavisualiseringer på denne måten? Og er det i det hele tatt mulig? Det er i hvert fall sikkert at dersom formatering og visuelle særtrekk ved datavisualiseringer kuttes ned til et minimum, er det ikke særlig mye igjen. Videre vil det å dele inn datavisualiseringer i ord-liknende segmenter være en svært utfordrende oppgave, kanskje ikke mulig i det hele tatt. Det er ikke sikkert en figur i en datavisualisering blir brukt til å formidle samme mening som en figur i en annen visualisering, og de omkringliggende grafiske elementene vil også være viktige. Det ser ut til at vi må tenke i retning av en løsning der datavisualiseringene kan bli sett på litt mer direkte, eller i det minste der konteksten og det visuelle uttrykket er bevart. Problemet er at skal vi gi tilgang som er uavhengig av websidene der de opprinnelig ble publisert, trenger vi mer omfattende adgang enn om vi bare gir forskerne lenkene til de originale kildene. Og lenker hjelper ikke særlig mye i internettets flyktige og raskt omskiftelige verden.
Ser du dilemmaet?
Referanse:
Davies, M. (2008). The Corpus of Contemporary American English (COCA): 560 million words, 1990 - present. https://corpus.byu.edu/coca/
Sinclair, J. M. (2004). Trust the Text: Language, Corpus and Discourse. (R. Carter, Ed.). London, UK: Routledge. http://ebookcentral.proquest.com/lib/agder/detail.action?docID=200411
Svartvik, J. (2007). Corpus linguistics 25+ years on. In Corpus linguistics 25 years on (Vol. 62, pp. 9–86). Amsterdam, Netherlands: Rodopi. Retrieved from https://ebookcentral.proquest.com/lib/agder/detail.action?docID=556853