
Nordisk dialektkorpus:
Eit avansert forskingsverktøy
Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.

Lansering
I dag blir dialektdatabasen Nordisk dialektkorpus offisielt lansert på ei tilstelning under konferansen 14. Møte om norsk språk i Tromsø. Det skjer på bokhandelen Akademisk Kvarter på universitetsområdet i Breivika med mellom anna språkrådsdirektør Arnfinn Muruvik Vonen til stades. (Sjå pressemelding frå Universitetet i Tromsø.)
Denne databasen er den første fellesnordiske dialektsamlinga nokonsinne, og til skilnad frå tradisjonelle dialektarkiv er den dessutan digital og elektronisk søkbar via internett. Truleg saknar den sidestykkje også utanfor Norden i innhald og funksjonalitet.

Omfattande innsamlingsarbeid
Forskingsinfrastrukturen er eit konkret resultat av samarbeidet om dokumentasjon og utforsking av grammatisk variasjon i det nordiske språkområdet som har pågått i snart eit tiår no: prosjektparaplyen Nordisk dialektsyntaks (ScanDiaSyn). Med støtte frå både nordiske og nasjonale finansieringskjelder har forskarar reist rundt i alle dei nordiske landa og gjort både opptak av fri tale og samla inn spørjeskjemabaserte opplysningar om grammatiske fenomen. I Noreg har vi besøkt drygt 100 stader og alt i alt har vi data frå over 200 stader i heile Norden (sjå karta på denne sida). Jamnt over har det vore minst fire informantar på kvar stad. Eg har tidlegare publisert nokre feltrapportar om innsamlingsarbeidet her på forsking.no – sjå mellom anna desse frå Sør-Troms, frå Lofoten og Vesterålen, frå Salten og frå Aust-Finnmark. Fleire feltrapportar er å finna på bloggen til prosjektet.
Lingvistisk forskingsinfrastruktur
Det er dei frie talemålsopptaka, både intervju og samtalar, som no føreligg i Nordisk dialektkorpus. Spørjeskjemadata vert tilgjengelege gjennom ein annan database som også er så godt som ferdig utvikla: Nordisk syntaksdatabase. Ansvaret for den tekniske utviklinga av begge desse forskingsinfrastrukturane har lege hjå forskargruppa ved Tekstlaboratoriet, Universitetet i Oslo.
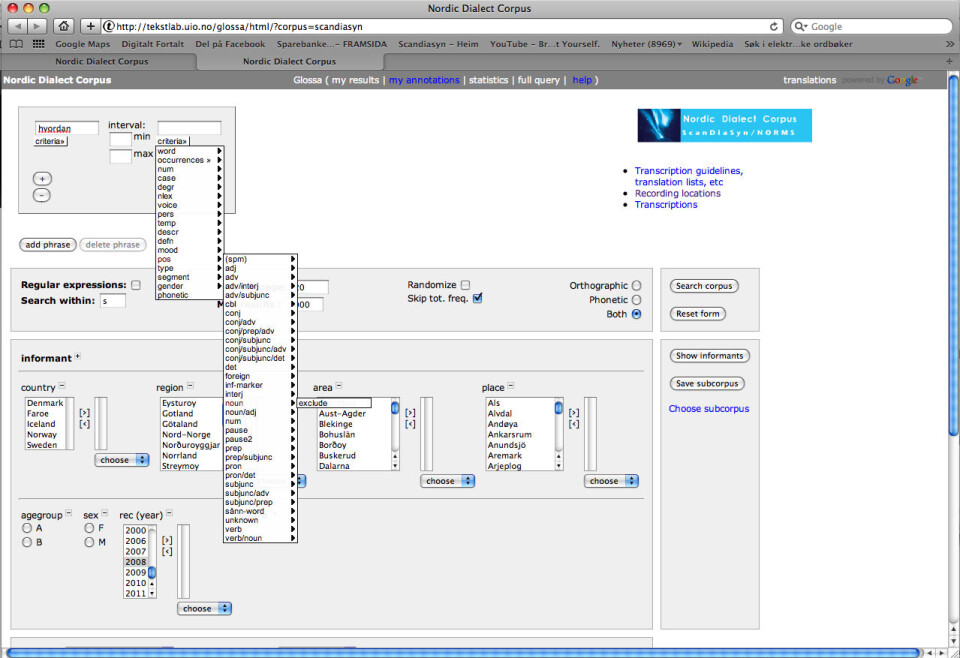
I Nordisk dialektkorpus er talemålsopptaka blitt transkriberte, i mange tilfelle både lydnært og ortografisk (standardspråkleg). Orda er så blitt automatisk handsama og utstyrte med grammatisk og leksikalsk informasjon (morfologisk tagga). Vidare er alle transkripsjonar kopla opp mot lyd- og videofiler. Gjennom eit brukarvennleg søkeskjema kan ein så søka på både ord, grammatiske kategoriar og sekvensar av dette og dessutan ei rekkje ikkje-språklege variablar slik som geografi, alder, kjønn med meir.
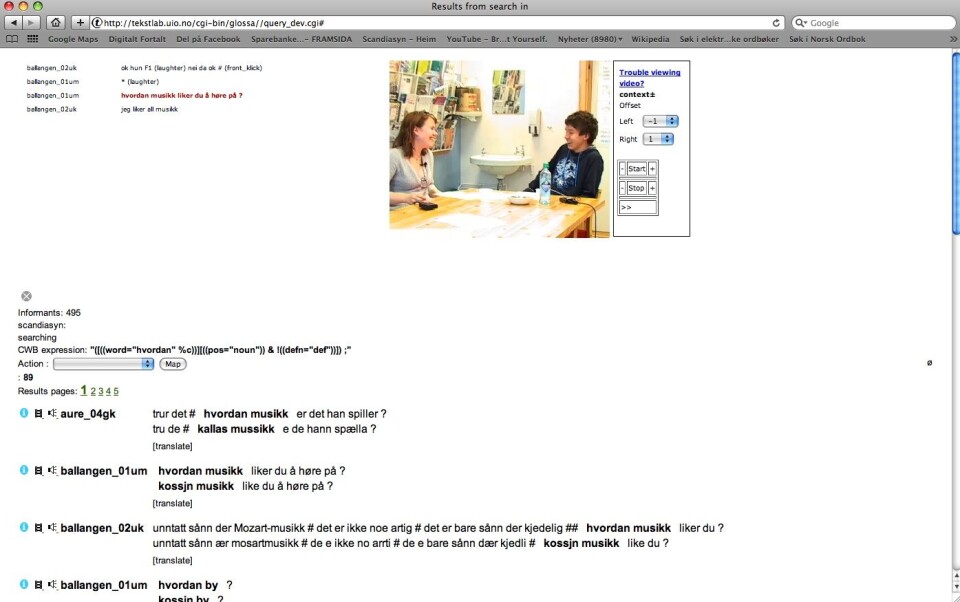
Resultathandsaming
Når ein så får opp søkeresultatet som ei liste av treff, kan ein for det første for kvart eksempel klikka seg inn på ein lyd- eller videosekvens som spelar av den aktuelle talesekvensen. Ein kan dessutan sortera resultatet på ulike måtar, redigera bort irrelevante treff, føreta ei teljing av treffa, få opp eit kartografisk grensesnitt for resultatet og mykje meir. (Tidlegare har eg faktisk skrive eit par innlegg her på forsking.no der eg har utnytta kartfunksjonen – nyleg eit stykkje om ordet for ‘pengar’ på flatbygdene og for eit år sidan om ulike former for personleg pronomen 2. person fleirtal i norske dialektar.)
Mange mulegheiter
I det heile gir dette dialektkorpuset ei rekkje nye mulegheiter for avansert komparativ talemålsforsking. Og eit viktig poeng er at databasen kan brukast til meir enn berre grammatikkforsking: Også for tradisjonell talemålsforsking med fokus på lyd- og bøyingslære og ordforråd, er korpuset av stor nytteverdi. Sidan det også er både gamle og unge informantar av begge kjønn på kvar stad, kan korpuset også nyttast til pilotstudiar av språkendring og til ein viss grad av annan sosiolingvistisk variasjon.
Nordisk meirverdi
Det har teke tid å realisera Nordisk dialektkorpus. Det ligg mykje arbeid bak og svært mange har bidrege på vegen, både i diskusjonar om korleis prosjektet skal utviklast og i sjølve utforminga. Det har vore ein stor styrke å ha det nordiske nettverket i botn, ikkje minst NORMS-prosjektet. Finansieringa har vore komplisert med løyvingar til eit vell av underprosjekt, nokre fellesnordiske og andre nasjonale i dei ulike landa. Og dei ulike løyvingane har ikkje alltid vore godt synkroniserte. Dette har gjort styringa av prosjektet komplisert – det enklaste hadde unekteleg vore om ein fekk alle pengane som ein stor pott med ein gong!
Historien om korleis prosjektet vart konsipert og korleis det har skride fram er vel verdt eit eige blogginnlegg. Det får bli ein annan gong. No er vi svært glade og stolte over å kunna lansera dette dialektkorpuset: Vi håpar mange av våre kollegaer også utanfor prosjektsamarbeidet vil ta det i bruk!