

AI som bidrar til å unngå miljøkatastrofer
Sammen med Equinor har vi bygd en AI-basert assistent for Equinors loggtolkere, som de nå bruker i sitt daglige arbeid.

Kunstig intelligens, også
kjent som AI, spiller en større og større rolle i arbeidslivet. AI hjelper oss
med beslutningsprosesser innen felt som medisin, transport, og
informasjonsinnhenting. Sammen med Equinor har vi lagt til et nytt felt på denne
lista, nemlig å tolke integritetslogger fra oljebrønner. Vi har bygd en
AI-basert assistent for Equinors loggtolkere, som de nå bruker i sitt daglige
arbeid.
En hjelpsom kollega
AI-verktøyet funker som en hjelpsom kollega som etter et par museklikk gir tolkeren en fullstendig tolkning av brønnintegritetsloggen som hun eller han jobber med.
Tolkeren kan så bruke denne automatiske tolkningen som utgangspunkt for sitt eget arbeid. Men som i mange andre felter der AI hjelper oss, er det den menneskelige eksperten som til slutt tar de endelige avgjørelsene og tar ansvaret for resultatet.
Dette verktøyet ble bygd som et samarbeidsprosjekt mellom Centre for Innovative Ultrasound Solutions (CIUS, NTNU) og Equinor. Vi fikk bidrag fra forskere på begge sider med lang erfaring med maskinlæring innen brønnintegritetslogger, samt bidrag fra erfarne brønnloggtolkningseksperter med mye domenekunnskap. De samme ekspertene er også blant verktøyets sluttbrukere.
Vårt maskinlæringsproblem
Å bygge et sånt verktøy var ikke helt enkelt. For å forklare hvorfor, må jeg først forklare maskinlæringsteknikken verktøyet er basert på. Vi brukte en «supervised» maskinlæringsalgoritme, som lærer oppgaven sin ved å se på matchende eksempler på inndata og utdata.
Prosessen kan sammenlignes med et veldig naivt barn, uten noen forståelse av verden rundt seg, som trenes til å kjenne igjen dyr ved å se på dyrebilder og bli fortalt hvilket dyr som er hvilket.
Uten noen forståelse av verden kan dette barnet lett ende opp med å lære assosiasjoner som funker for treningsbildene men ikke funker generelt – for eksempel at ethvert dyr med munnen åpen og tunga ute er en hund.
Oppgaven blir enda vanskeligere hvis noen av dyrebildene er litt uklare, hvis bildene viser mange andre ting enn selve dyret, eller hvis barnet iblant får feil dyr som fasit.


For vårt verktøy er inndataen ikke dyrebilder, men brønnintegritetslogger, og fasiten er ikke dyrenavn, men eksperttolkninger av disse loggene. Som i alle komplekse tolkningsoppgaver vil forskjellige tolkere til en viss grad være uenige – og en tolker er heller ikke 100 prosent konsistent fra dag til dag. Dette gjør at fasiten til maskinlæringsalgoritmen blir litt tvetydig. For å trene algoritmen bedre, er det viktig å sørge for at fasiten blir så entydig som mulig.
Utover det, er brønnloggdataen som brukes som inndata også kompleks – den inneholder mange forskjellige typer informasjon, og mye av det er ikke direkte nyttig for å forutsi hva tolkningen burde være.
Noen av dataene er til og med rett og slett feilmålinger, men heldigvis har disse et regelmessig mønster som gjør det enkelt for menneskelige tolkere å kjenne dem igjen og se bort fra dem. En maskinlæringsalgoritme, derimot, er veldig naiv, og klarer ikke like lett å se bort fra disse feilmålingene!
Bedre maskinlæring
I dette samarbeidsprosjektet mellom CIUS og Equinor gjorde vi noen store framskritt fra arbeidet vi har publisert tidligere. Disse framskrittene førte til at de automatiske tolkningene ble mye bedre.
På inndatasida utviklet vi en enkel og tilstrekkelig robust metode for å identifisere og filtrere ut skrotdata. Vi forbedret også metodene våre for å bryte ned loggedataen før vi matet den som inndata til maskinlæringsalgoritmen.
På utdatasida førte det tette samarbeidet med Equinors tolkningseksperter til store forbedringer fra vårt tidligere arbeid i CIUS, som var basert på eldre logger fra Equinor. Disse eldre loggene brukte et tolkningsskjema som ligner det som er vanlig å bruke ellers i industrien.
Siden den gang har Equinor utviklet og tatt i bruk et forbedret tolkningsskjema, som tillater mer presisjon og objektivitet enn det gamle. Det nye skjemaet gjorde dermed læringsjobben til maskinlæringsalgoritmen lettere, som vi tydelig så føre til at den gjorde en klart bedre jobb.
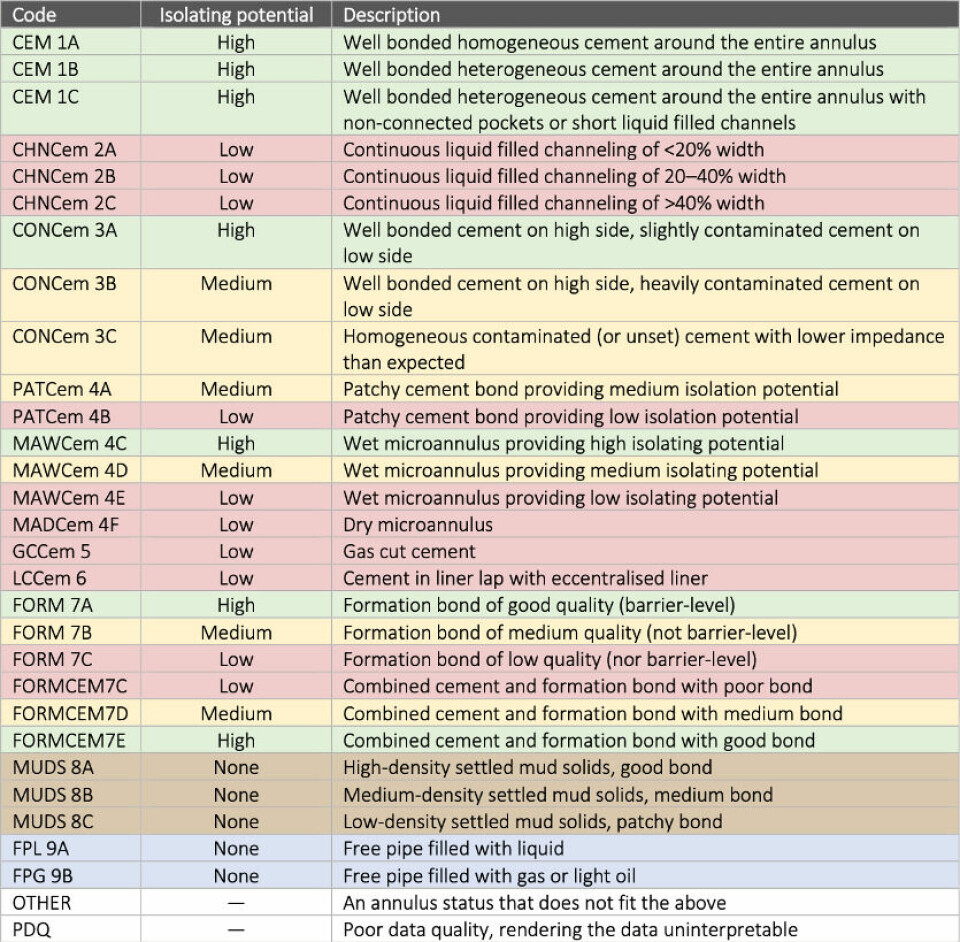
Hvordan angir man en brønnloggtolkning?
I den forrige saken min ga jeg et enkelt eksempel
på hvordan en tolker kan tenke når hun eller han analyserer en brønnlogg. Men
hvordan ser den endelige tolkningen ut? I korte trekk, deler tolkeren den
loggede lengden av brønnen opp i lengdeintervaller ut fra hva loggen viser i
disse intervallene. Deretter må de bruke et tolkningsskjema for å angi
statusen til hvert intervall.
For å
gjøre dette klarere, la oss ta for oss et tankeeksempel der en loggtolker ser
på en logg målt mellom 1000 m og 2000 m langs lengden av røret. Loggen er
heldigvis enkel og kan entydig deles inn i fire intervaller:
- 1000–1500 m: Kun væske utenfor røret
- 1500–1700 m: Veldig god og jevn sement utenfor røret
- 1700–1800 m: Usammenhengende sement som ikke nødvendigvis forsegler brønnen godt
- 1800–2000 m: Veldig god men litt ujevn sement utenfor røret
Tolkeren må så angi statusen til hvert intervall ifølge tolkningsskjemaet som bedriften følger. Mange bedrifter bruker skjemaer som angir kvaliteten til sementen som sitter på utsiden av røret etter en skala: Den kan være “bra”, “middels til bra”, “middels”, “dårlig til middels” eller “dårlig”. (Noen skjemaer har også en klasse for “fritt rør”, som betyr kun væske eller gass utenfor røret.)
For denne loggen angir tolkeren intervallene fra topp til bunn som “dårlig”, “bra”, “middels”, og “bra”. Tolkerens litt strengere kollega, derimot, er helt enig i hva loggen viser, men vil heller angi intervallene som “dårlig”, “bra”, “dårlig til middels”, og “middels til bra”. Dette viser hvordan en slik tolkningsskala fører til veldig subjektive vurderinger, selv om begge tolkerne uansett er enige i at brønnen alt i alt virker godt forseglet pga. den gode sementen mellom 1500 og 1700 m.
Equinors nye tolkningsskjema, som tabellen i nærheten viser, lar derimot tolkerne angi mer spesifikt hva de mener er bak røret. I dette tilfellet er det lettere for de to tolkerne å enes om at intervallene skal angis som “FPL 9A”, “CEM 1A”, “PATCem 4A” og “CEM 1B”. Selv om det fortsatt er noe rom for uenighet, er det lettere å bli enige når tolkningsskjemaet er mer håndfast!
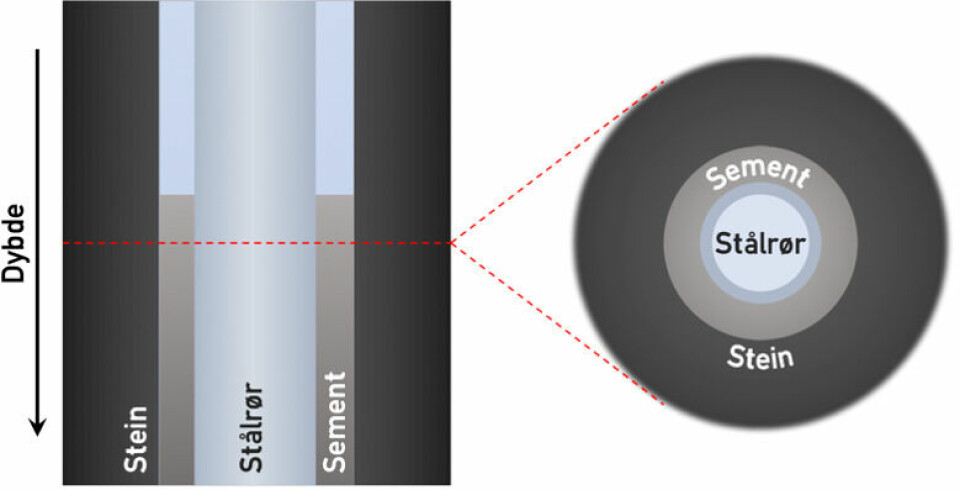
Bildet over viser to tverrsnitt av en oljebrønn, nær toppen av sementen. (Illustrasjon: Erlend Magnus Viggen/NTNU)
Utover det, konstruerte prosjektets eksperter på brønnloggtolkning et loggedatasett av høy kvalitet for å trene og teste maskinlæringa. De tok et sett med logger som Equinor hadde tolket tidligere, så bort fra logger som var for tvetydige til å funke som treningseksempler, og gjorde en ekstra kvalitetskontroll for å forbedre den indre konsistensen til datasettet.
Verktøyet i dag
I løpet av prosjektet integrerte vi tolkningsassistentverktøyet vårt inn i programmet som Equinors brønnloggtolkere bruker. Dermed kan de enkelt bruke verktøyet som del av deres daglige arbeidsflyt. Equinors tolkere gjør nå derfor utstrakt bruk av verktøyet, og Equinor står selv for vedlikehold, forbedringer og utvidelser av verktøyet.
Med andre ord: Ikke bare hjelper verktøyet tolkerne til Equinor med å gjøre en god jobb med å forhindre miljøkatastrofer ved å sørge for at brønnene deres er trygge – det kommer bare til å bli bedre og bedre til sin jobb som assistent til brønnlogtolkerne.
I tillegg planlegger Equinor å offentliggjøre kildekoden til verktøyet for å la andre selskaper kunne bruke det. På den måten håper de å kunne komme hele industrien til gode ved å tilby et verktøy som kan bidra til at oljebrønner over hele verden er sikre.
Vil du vite mer? Hvis du vil ha et mer teknisk overblikk over hva vi har gjort av forbedringer og implementering siden den forrige saken min om automatisk brønnloggtolkning, har jeg også en mer detaljert engelskspråklig post på min personlige nettside. Du finner også mer utfyllende informasjon i en vitenskapelig artikkel som vi publiserte i journalen SPE Drilling & Completion