
Dyplæring i bakevja
Hva gjør man når man har samlet inn 6000 timer med video, men ikke har tid til å se gjennom alt? Tar kontakt med smarte dataingeniørstudenter, selvfølgelig!


Et sentralt tema på bloggen er fisken i landskapet og hvordan fisk flytter seg rundt i forhold til sesonger, miljøforhold og livshistorie. Vårgytende fisk her i nord er avhengig av gunstige temperaturer som sikrer klekking av eggene i løpet av noen dager og rask utvikling av yngelen i løpet av en kort og hektisk vår- og sommersesong.
Høyere temperatur og roligere strømningsforhold finner vi hovedsakelig på grunnområder i innsjøer og i bakevjer og flommark i elver, der vannet varmes opp raskere enn det kalde smeltevannet i hovedløpet.
Vi har studert gjedde, abbor, stingsild og karpefisk i deres sesongmessige habitater i Lågendeltaet over flere år, og vi har hatt spesielt fokus på en bakevje som er forbundet til Lågen ved vannføringer over 250 kubikk.
Her har vi montert et undervannskamera som har filmet innsiget av fisk under vårflommen, når vannet stiger og det blir kontakt inn til bakevja. Dette skjer typisk i midten av mai måned, pluss/minus et par uker.
I løpet av de siste årene har vi samlet tusenvis av timer med opptak - som betyr mange terrabyte med digitale videofiler. Målet har vært å dokumentere hvilke arter som bruker bakevja, hvilket tidspunkt på året de ankommer, og hvordan vannføringen i Lågen påvirker tidspunktet for ankomsten.

Video er en skånsom overvåkingsmetode – vi får et innblikk i økologien under vann uten å stresse gyteklar fisk med fangst og håndtering. Men å se gjennom alt materialet manuelt er nærmest umulig: dersom man skulle identifisert arter og talt antall individer ville vi brukt cirka like lang tid som selve opptaket. Et årsverk er cirka 1900 timer og da sier det seg selv at jobben er uløselig ved bruk av menneskelig arbeidskraft.

Videomaterialet kan imidlertid brukes til trening av dataprogrammer som kan automatisere gjennomgangen av resten av materialet. Vi fiskebiologer hadde imidlertid ett problem: vi visste ikke hvordan vi skulle angripe problemet rent teknisk. Heldigvis fikk vi kontakt med teknologimiljøet på NTNU i Gjøvik, som i mange år har jobbet med bruk og utvikling av maskinsyn og maskinlæringsteknikker.
NTNU har vært framsynte nok til at de legger til rette for at deres studenter kan løse oppdrag på vegne av privat næringsliv, offentlig forvaltning – og andre forskningsmiljøer. Studentene får erfaring med å jobbe med klienter uten programmeringskompetanse, mens oppdragsgiverne for løst problemet sitt. Vinn-vinn, med andre ord!
Oppdraget vi ga studentgruppa var følgende: vi trenger et dataprogram som automatisk kan gå gjennom videomaterialet og trekke ut informasjon om antall fisk av forskjellige arter.
Dette faller under kategorien maskinsyn, der programmer kan kategorisere innholdet i bilder og film og tilegne det mening eller informasjon – omtrent som hvordan Microsoft Excel kan sortere innholdet i celler basert på verdiene: Man må bare fortelle programmet hva det skal lete etter – og det er langt mer komplekst enn tallverdier i en celle.
«Tradisjonelt» maskinsyn har vært en del av samfunnet i et par tiår allerede. Tenk bare på skiltgjenkjenning på bilen og hvordan du plutselig får en regning etter å ha passert en bom på en grusvei eller en parkeringsplass: Programmet trekker ut informasjon fra bildet av bilen din og er trent til å se etter en hvit eller grønn rektangulær plate med bokstaver og tall.
Moderne maskinsyn er i større grad en gren innenfor dyplæring. Her er det komplekse (tredimensjonale) ting i bevegelse med mye støy rundt, og algoritmen må lære hva den skal trekke ut av informasjon. Prinsippet om gjenkjenning er imidlertid det samme som i tradisjonelt maskinsyn: man må trene opp algoritmen til å «se» etter de tingene man er interessert i. Og for fiskeforskere er jo det nettopp fisk.

Gruppa startet derfor med å «lære» programmet hva det skal se etter. Dette gjøres ved å annotere bilder, det vil si å definere at «dette er en abbor, dette er en mort, dette er en gjedde» osv.
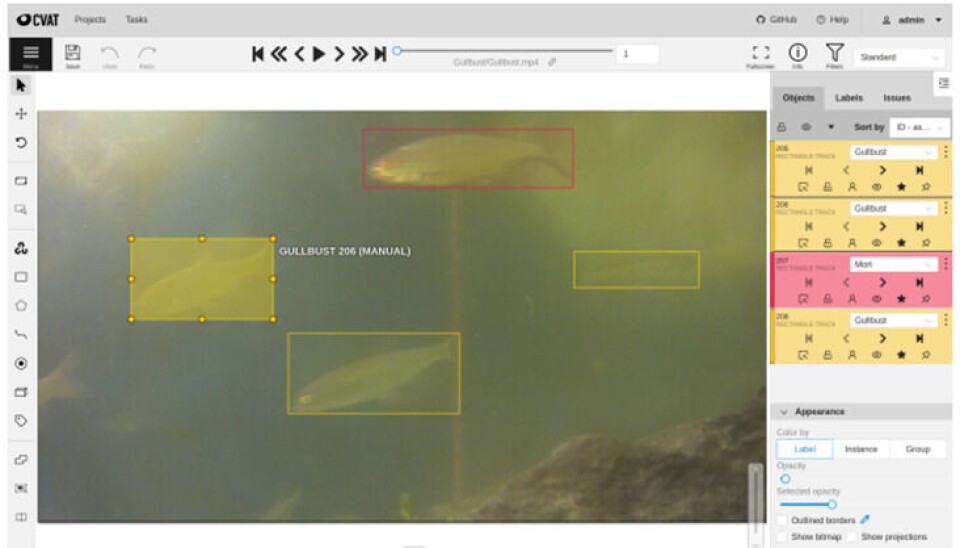
Etter rundt 50 000 annoteringer skulle man tro at arbeidet var ferdig, men ettersom dette er video og ikke bare stillbilder måtte gruppa også lage en modul som sporer enkeltfisk fra bilde til bilde. Slik unngår man at et individ blir talt i hvert stillbilde, og dette er jo veldig viktig ettersom opptakene inneholder opptil 30 bilder per sekund. Prosessen blir derfor mer komplisert enn analyse av stillbilder.

Selve arkitekturen som ble benyttet er et kunstig nevralt nettverk: metodikken kan se igjennom bilder og trekke ut informasjon som ligner på det den har blitt trent til å gjenkjenne («Dette er en abbor, dette er en gjedde osv.»), selv om fisken beveger seg i alle mulige retninger og vannet kan være grumsete.
Klassifiseringen må skje raskt og effektivt slik at programmet ikke bruker unødvendig lang tid. Nevrale nettverk – som etterligner vår egen hjerne – viser seg å være en veldig effektive til å analysere komplekse bilder og trekke ut informasjon.
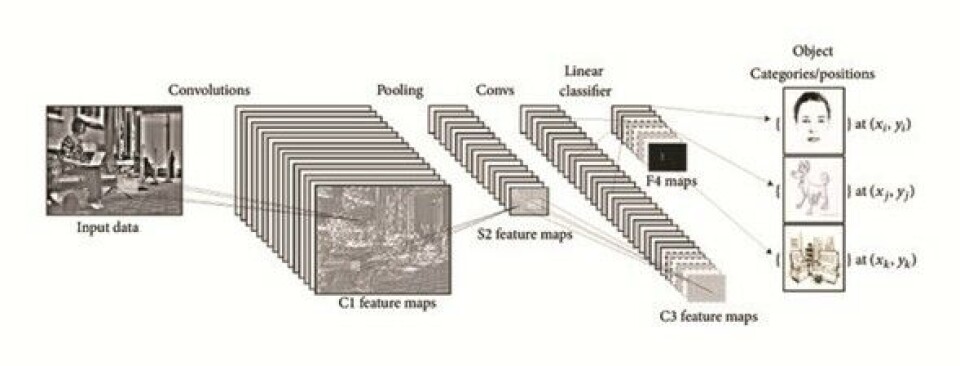
Hvordan arbeidsflyten og prosesseringen defineres er derfor svært viktig når man skal håndtere store mengder video. I løpet av et vårsemester kodet gruppa et program som klarte å hente ut informasjon fra video på samme måte som en (menneskelig) observatør ville kunne gjort det, bare mye raskere:
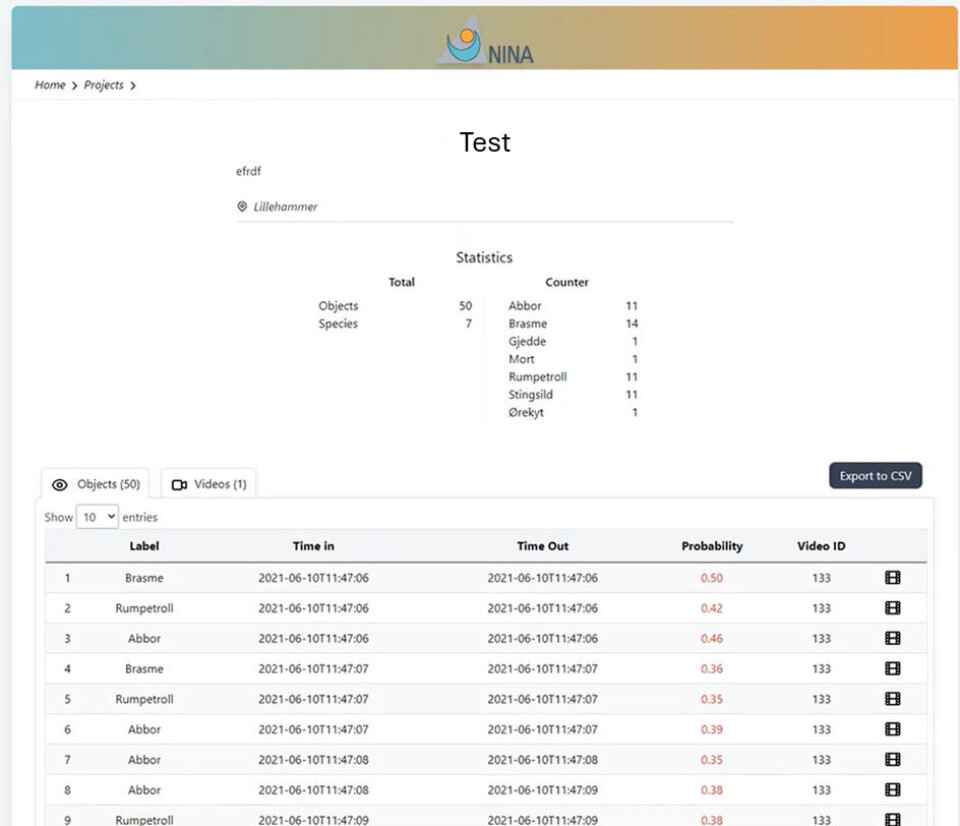
Video mates gjennom programmet, og etter prosesseringen genererer programmet en sannsynlighetsfordeling for hver fisk som har blitt identifisert i løpet av en videosnutt og teller antall fisk av hver art!
Arbeidet er på mange måter et nybrottsarbeid som er verdt å dele i den vitenskapelige litteraturen, og studiet er nå publisert i tidsskriftet Ecohydrology. Her hadde vi fokus på å vise hvordan teknologien kan benyttes av fiskeforskere når målet er å overvåke fiskebestander under sårbare perioder, slik som gytetiden.
Vi testet også programmet på et større materiale med flere ulike miljøforhold, for å sjekke grensene for hva som er mulig med denne versjonen.
Bakgrunnen for testene var en fasit, med antall av hver art i et utvalg videoklipp som dekket hele sesongen. Her satt vi og nistirret på skjermen og telte abbor og gullbust i over hundre 30-sekundersklipp. Deretter kjørte vi det samme videomaterialet gjennom programmet og sammenlignet antall fisk fra de to metodene ved ulike grenser for treffsikkerhet.
Vi ønsket at programmet skulle være restriktivt nok til at kun de riktige objektene ble klassifisert (dvs. hindre overestimering), men samtidig liberalt nok til at vi ikke gikk glipp av noen objekter (dvs. hindre underestimering).
Ikke uventet fant vi best samsvar mellom modellens prediksjoner og vår fasit når vi trakk ut enkeltbilder fra sporet til en enkeltfisk med en høy sannsynlighet for riktig klassifisering. Når grensen for treffsikkerhet ble økt traff programmet generelt bedre – og dette skyldtes mindre overestimering heller enn et fall i underestimering.
Det var også en betydelig variasjon mellom artene, og modellen fungerte best for mort, gjedde og rumpetroll. Det var faktisk ingen tydelige effekter av sikt, lys og algevekst på linsen.
Konklusjonen fra studien er at maskinsyn kan være et effektivt alternativ til fangstbaserte studier når man ikke trenger å måle eller merke enkeltfisk. Presisjonen øker med større annoterte treningssett, og avgjørelser rundt statistiske utvalg til analyser må fremdeles tas på lik linje med annen datainnsamling.
Denne opprinnelige modellen har senere blitt videreforedlet av nok en gruppe på NTNU. Å bygge videre på eksisterende arbeid er effektivt, spesielt når grunnlaget er så godt som dette! Det er mye snakk om kunstig intelligens for tiden, noen ganger med et negativt fortegn, men man kan altså bruke teknologien til å artsbestemme og telle ferskvannsfisk i Gudbrandsdalen!

Referanser:
Artsgjenkjenning av fisk (bacheloroppgave)
Monitoring Fish Assemblages in Seasonal Off- Channel Habitats Using Underwater Video and Computer Vision. Åpent tilgjengelig versjon Myrvold mfl. (2025a):
Lenke til artikkelen (bak abonnementsmur) Myrvold mfl. (2025b):